Research
Project 1: System-Level Optimziation for Applied Machine Learning
 Description:
Description:
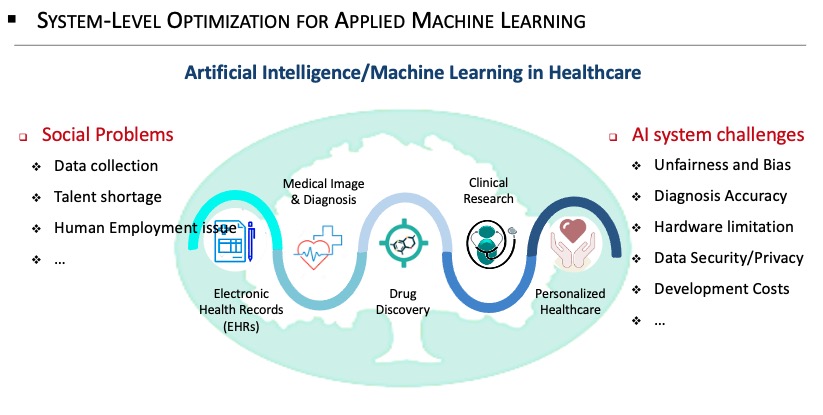
Applying machine learning (ML) for different applications has been widely studied from the algorithmic level. These applications, however, can take effects only when they can be deployed to the computing devices. This requirement brings us to the second wave of AI democratization, i.e., the needs of system-level optimization for ML applications. The challenges in this wave is to identify the unique requirement from different ML applications, and provide automation solutions to build the system on the resource constrained computing devices. Working with my Ph.D. students, our recent research focuses on the fairness issue in medical AI, collaborative and privacy requirements in drug discovery, and real-time demands in subsurface estimation.
 1. Fairness in AI-assistant healthcare
1. Fairness in AI-assistant healthcare
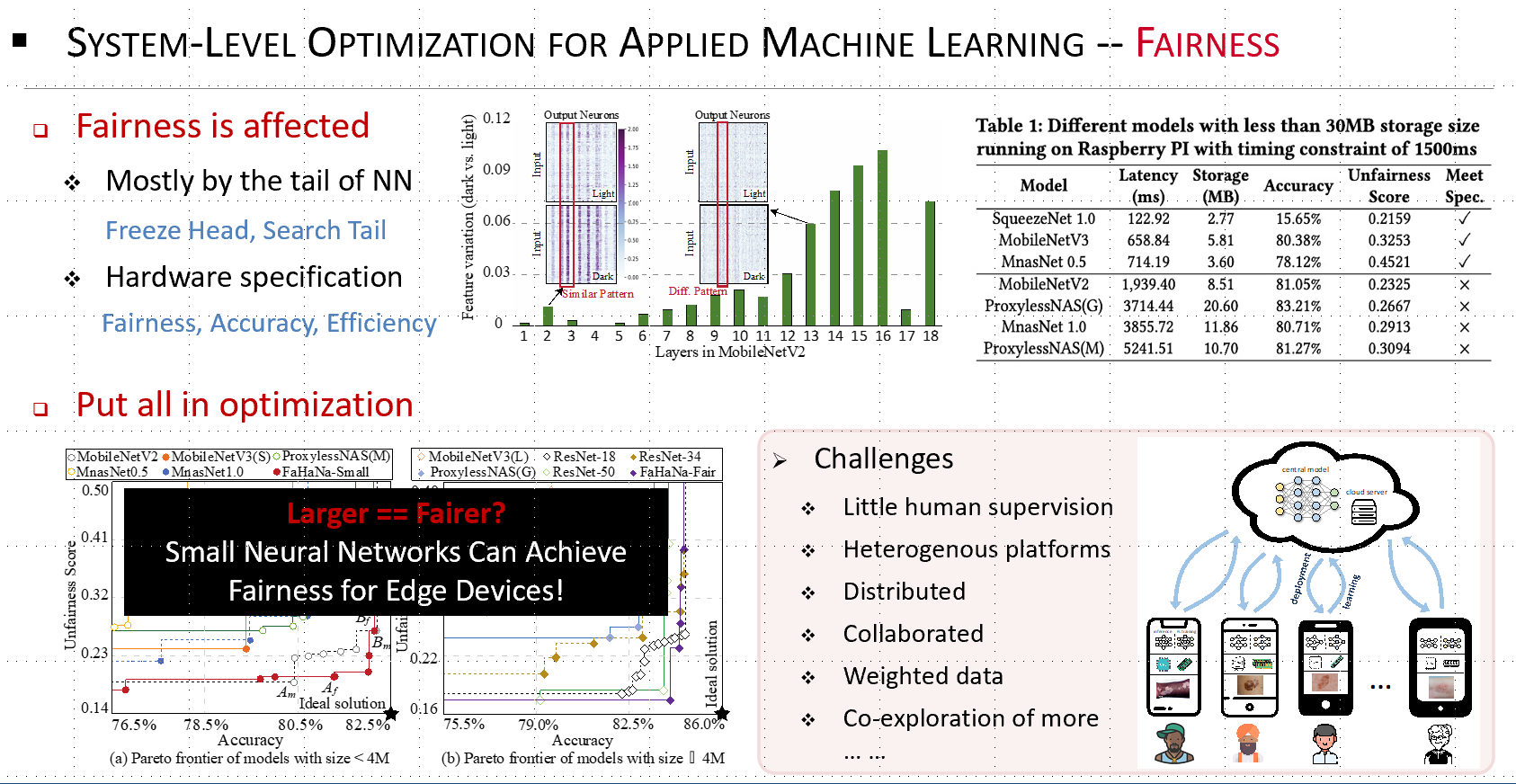
AI models have been deployed in an increasing number of healthcare applications, from mobile dermatology assistant, mobile eye cancer (leukoria) detection, emotion detection, to medical imaging and diagnostics, all pointed out significant gender and skin-type bias in commercial AI systems. To address such racial, skin color, and socioeconomic inequities, my research is to address the fairness issue from the system level by providing federated learning platform to collect equitable demographic dataset instead of relying on all the private companies. In this project, we are addressing challenges, including: 1) It is essential to achieve this goal with as little human supervision as possible since it is impractical to have a doctor to constantly label the images. 2) Not everyone has the same hardware. To ensure the participation of the population from all socioeconomic status, the hardware devices have to be heterogeneous. 3) Not all machine learning models are the same. Better unsupervised learning capability calls for a larger neural network. However, a larger network needs more memory and computation resources, which places additional pressure on the already limited resources. Also, some models will be intrinsically fairer than others. How to obtain the best model for fairness is also important.
 2. Collaborative and privacy-preserving federated learning for drug discovery
2. Collaborative and privacy-preserving federated learning for drug discovery
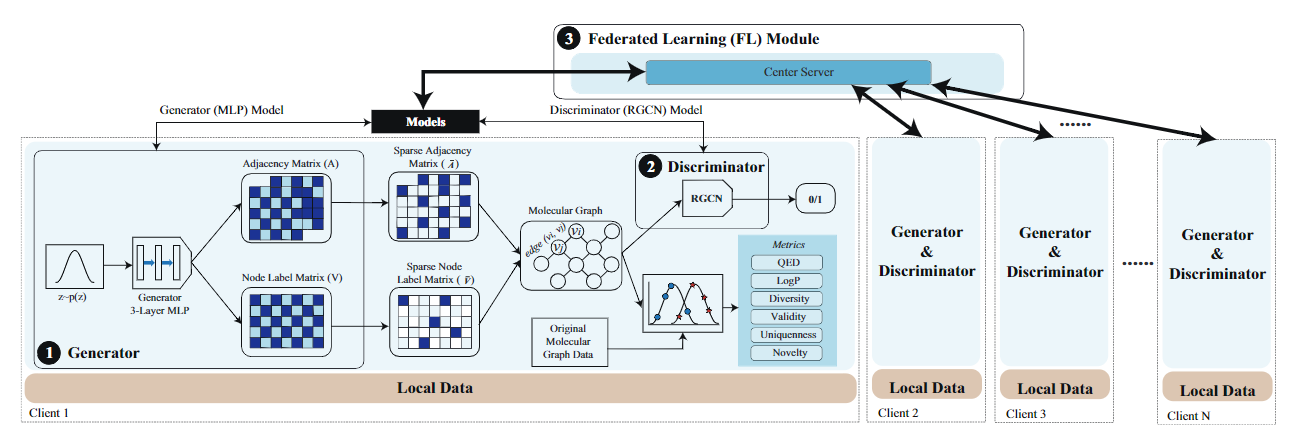
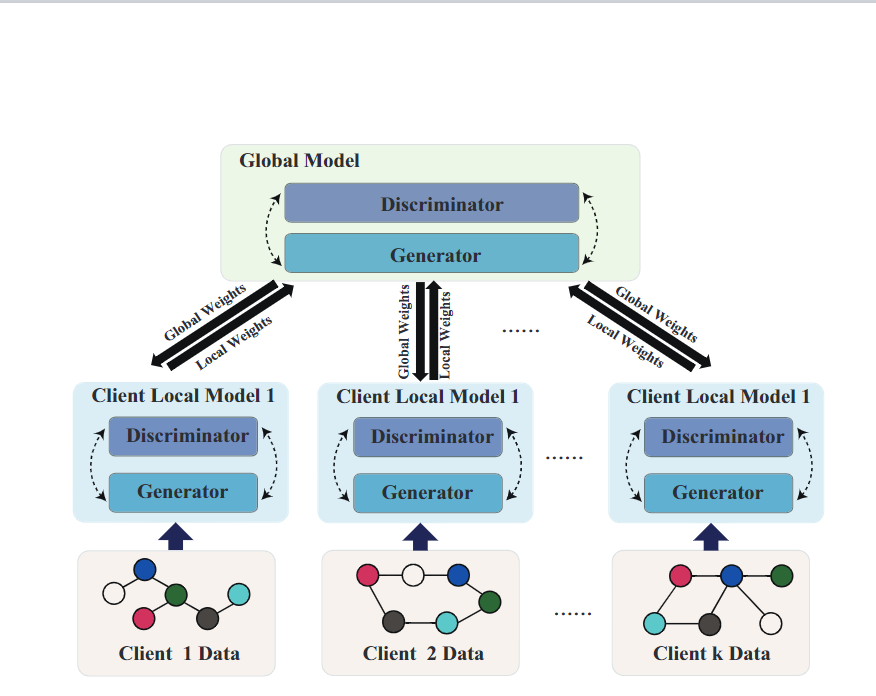
The outbreak of the global COVID-19 pandemic emphasizes the importance of collaborative drug discovery for high effectiveness; however, due to the stringent data regulation, data privacy becomes an imminent issue needing to be addressed to enable collaborative drug discovery. In addition to the data privacy issue, the efficiency of drug discovery is another key objective since infectious diseases spread exponentially and effectively conducting drug discovery could save lives. On the other hand, machine learning has demonstrated its ability to address these issues: for data privacy in collaborative drug discovery, federated learning is a good candidate; for efficient drug discovery, the Graph Neural Network (GNN)-based Generative Adversarial Network (GAN) has been used in pharmaceutical companies. But, it still lacks a holistic framework to provide system support for efficient, collaborative and privacy-preserving drug discovery. In ICCAD’21, we proposed the first collaborative and privacy-preserving Federated Learning framework, integrating GANs for molecular generation and GNNs for learning structural properties of molecular graph.
Project 2: Auto-ML: Hardware and Software Co-exploration for Neural Network Architectures
 Description:
Description:
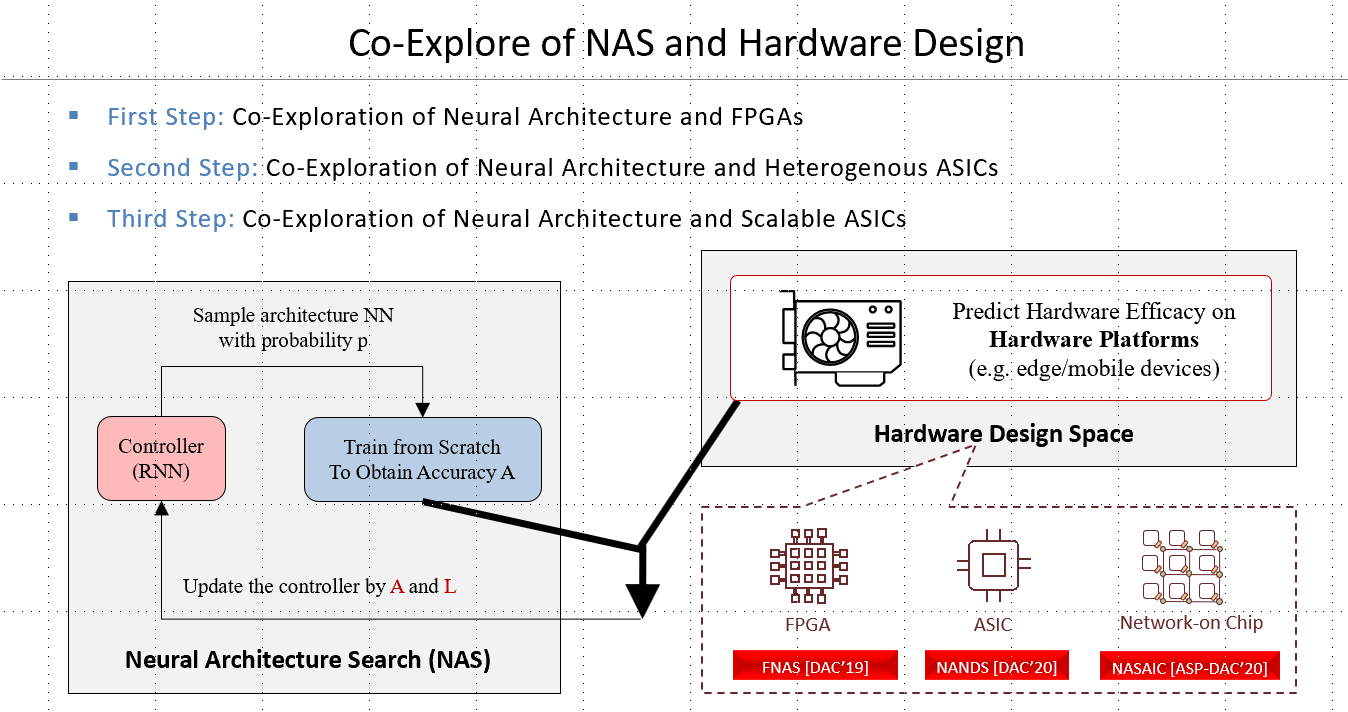
With AI democratization, Neural Architecture Search (NAS) emerges to automatically identify neural architecture with state-of-the-art accuracy. However, existing works without the consideration of hardware efficiency cannot guarantee the hardware design specifications to be met, rendering the identified neural architectures useless. The fundamental problem is that there exists a gap between NAS and hardware design. To solve this problem, we first proposed the philosophy of HW/SW co-exploration for neural architectures. Our proposed novel frameworks have not only bridged neural architecture design and hardware optimization, but also significantly pushed forward the Pareto frontier in terms of the tradeoff between accuracy and efficiency. We have proposed the co-design frameworks for the explorations of neural architectures, respectively, with FPGA, ASICs and Network-on-Chip architecture design.
 1. FNAS: Co-explorations of neural architectures and FPGA
1. FNAS: Co-explorations of neural architectures and FPGA
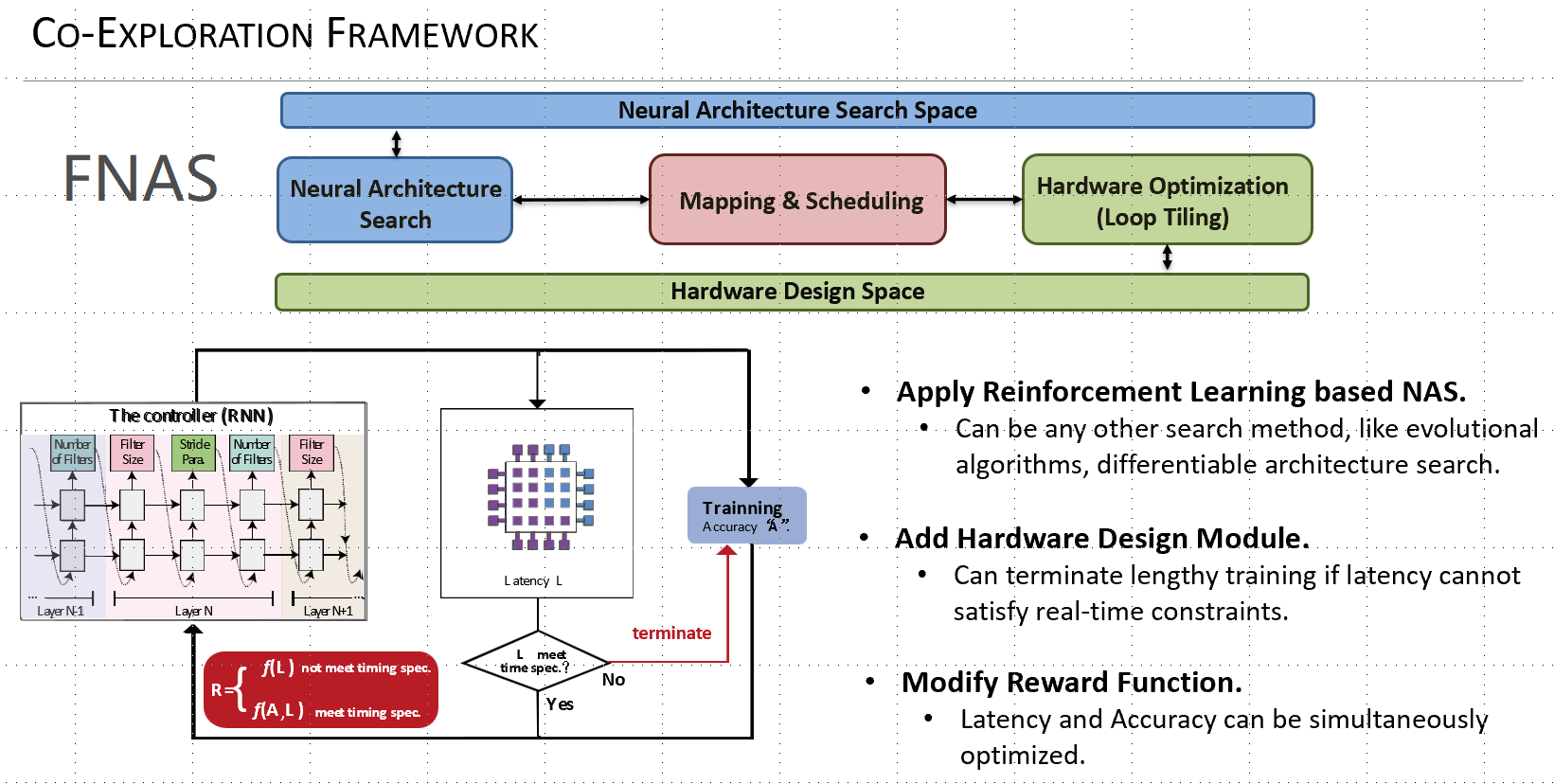
With incomparable high-efficiency over GPU for real-time inference (batch size of 1), FPGA has gradually become one of the most popular machine learning hardware platforms, especially for real-time edge computing. Taking FPGA as a vehicle, we proposed the first framework of co-exploration of neural architectures where the architectures stand for both neural network architecture and neural accelerator architecture, as shown in Figure 2. This work successfully involves FPGA optimization in the search loop for the first time. We demonstrate that without considering the hardware design, the identified architecture by NAS cannot be accommodated on the edge FPGA; however, the co-exploration can guarantee the hardware design specification to be met, while providing the comparable accuracy. This work obtained IEEE Transactions on CAD Donald O. Pederson Best Paper Award and was nominated for the best paper in DAC’19.
 2. NASAIC: Co-explorations of neural architectures and ASICs
2. NASAIC: Co-explorations of neural architectures and ASICs
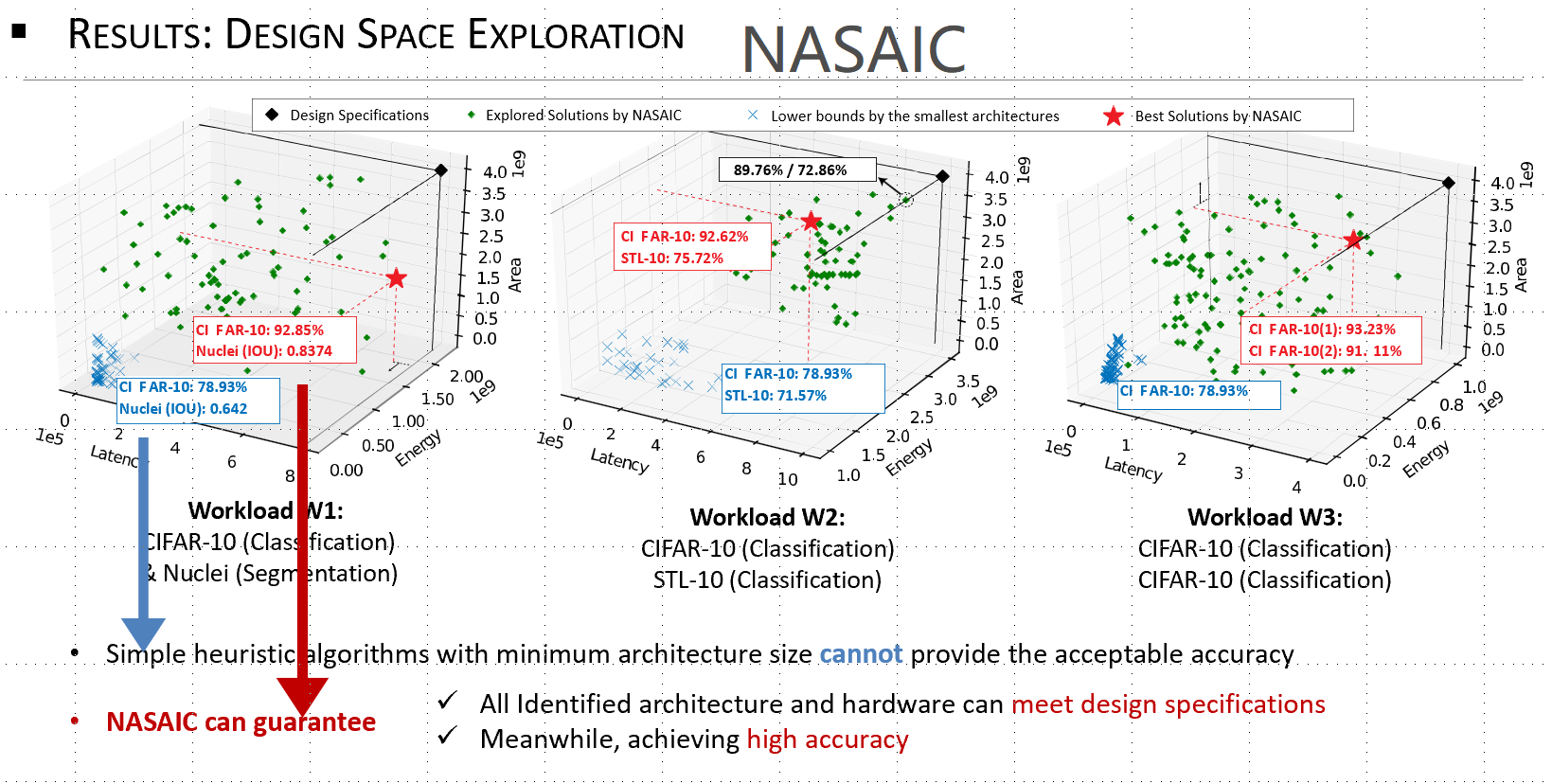
Among all AI accelerating platforms, ASICs provide incomparable energy efficiency, latency, and form factor. Though seemingly straightforward, integrating NAS with ASIC design is not a simple matter, primarily due to the large design space of ASICs where a same set of PEs can constitute numerous topologies (thus dataflows). Collaborated with researchers from Facebook and Georgia Institute of Technology, we proposed the first NAS and ASICs co-exploration framework. Instead of a full-blown exploration of the design space, a set of ASIC templates are built on top of existing great ASIC accelerator designs. As such, the design space can be significantly narrowed down to the selection of templates to form a heterogeneous accelerator (with multiple types of dataflow). This work has been published at DAC’20.
 3. NANDS: Co-explorations of neural architectures and scalable NoC
3. NANDS: Co-explorations of neural architectures and scalable NoC
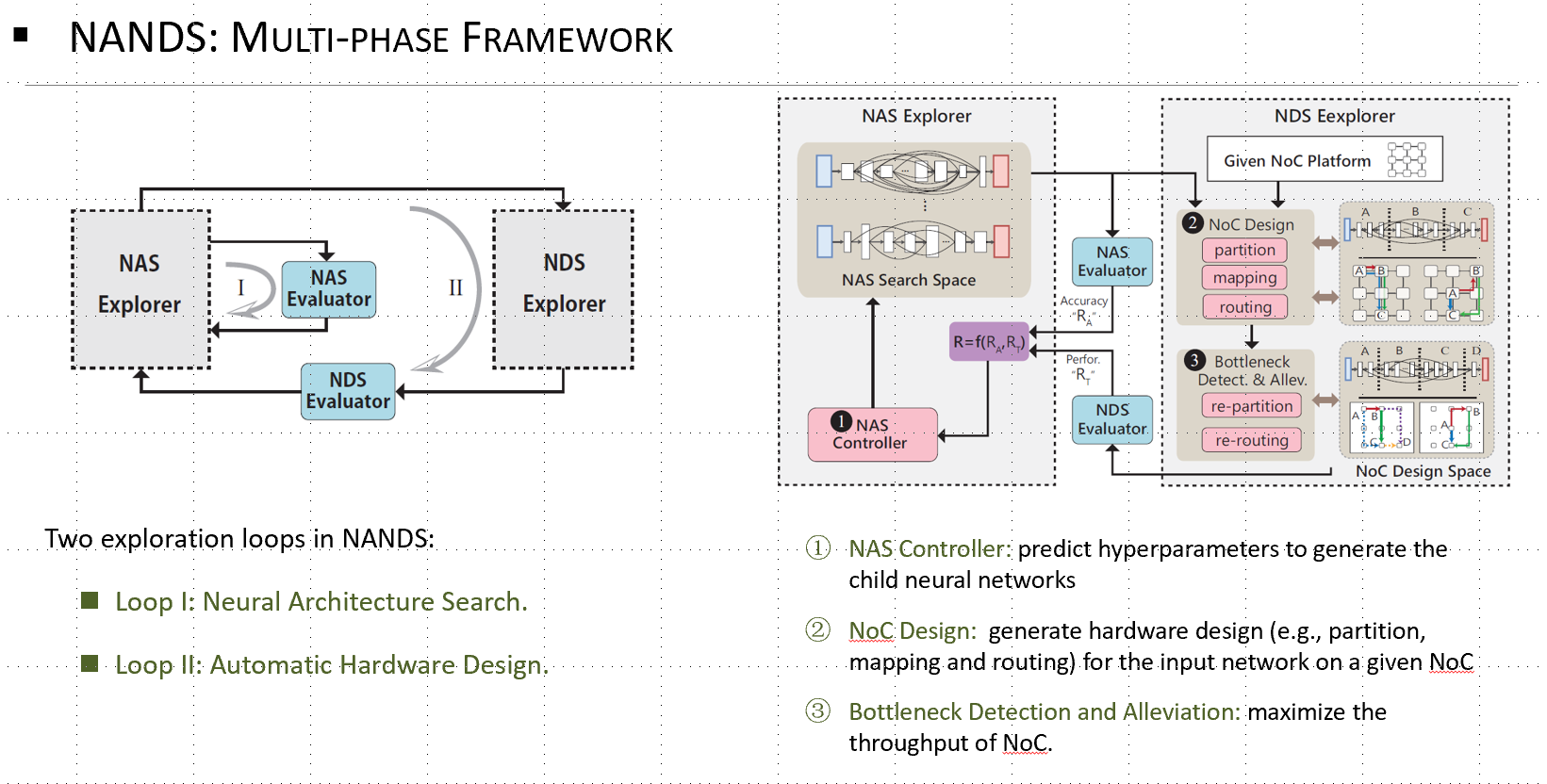
For applications with extremely high real-time requirements, system size will scale up and it is inevitable that communication will become performance bottleneck. Network-on-Chip (NoC) is one of the most promising infrastructures for large-scale FPGA/ASIC systems. In this work, a co-exploration framework was proposed, targeting simultaneous optimizations of neural architectures and NoC communication protocols. This work is nominated for the best paper in ASP-DAC’20.